 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文2024-01-24 关键词:医疗大模型
2023年被很多人称为“医疗大模型的元年”,国内外均有大量厂家将大语言模型应用于医疗健康领域。据统计,截至2023年10月,我国累计公开的大模型数量已经达到238个,垂直类大模型达到103个。而2-9月,我国发布的医疗大模型近50个,涉及智慧诊疗、医疗文本处理、药物研发和学术科研等多个方面。医疗大模型是否能够帮助临床医生和医疗机构提升医疗质量?2024年医疗大模型又将面对哪些困难?为探寻答案,CDSreport整理了相关资料。
医疗大模型效果将逐步得到验证
2023年6月,四川大学华西医院信息中心刘加林教授团队在医学权威期刊Journal of Medical Internet Research上发表了研究文章“Utility of ChatGPT in Clinical Practice”,证明了ChatGPT在临床多个环节为医务人员提供了有效的诊疗决策支持。
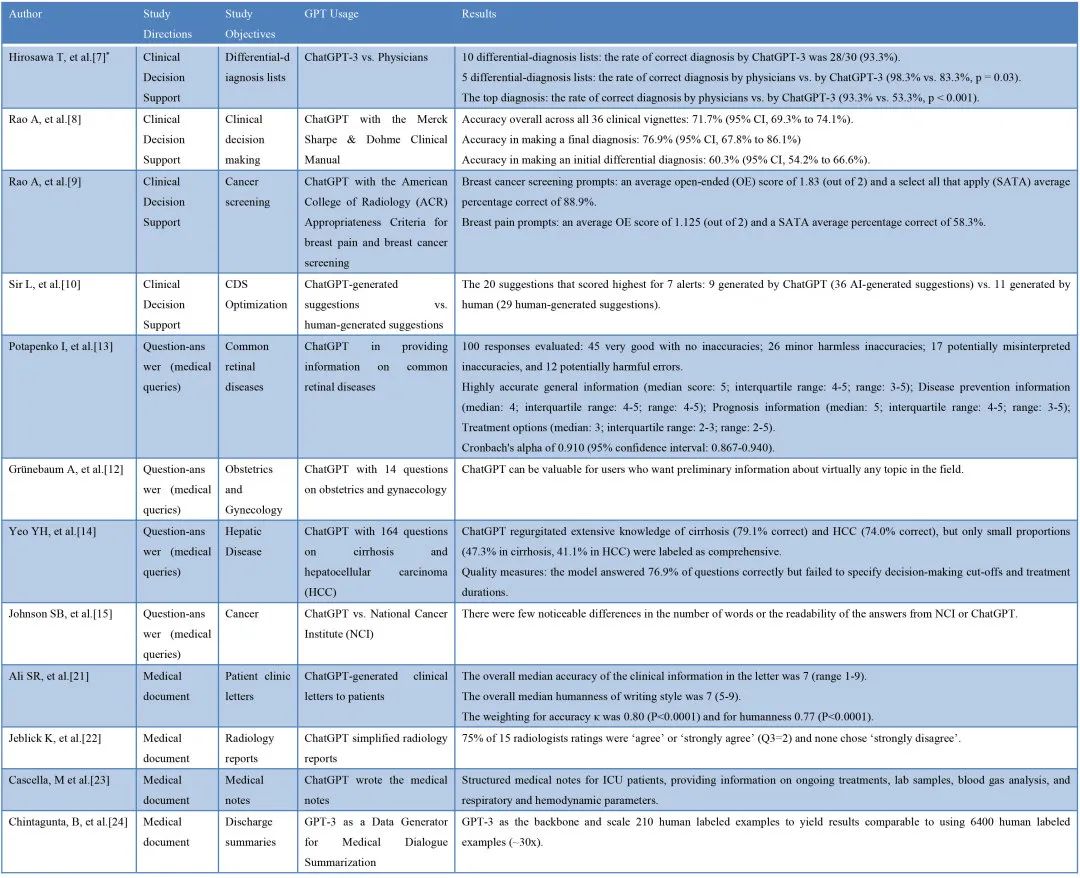
ChatGPT在临床实践中的应用
研究显示,基于大语言模型的人工智能ChatGPT在临床实践中展现出巨大的潜力,或将彻底改变现有的医疗模式。例如,在诊断方面,ChatGPT在常见病的正确诊断率高达93.3%。在临床决策方面,再根据多个维度比较了36个病例的鉴别诊断、诊断测试、最终诊断和处理的准确性后,ChatGPT的总体准确率达到了71.7%(95% CI,69.3%~74.1%)。此外,ChatGPT还可用于癌症筛查和优化临床决策支持系统,为医生提供重要的辅助信息。
在回答医学问题方面,ChatGPT也展现出了强大的能力。例如,在视网膜疾病、产科和妇科、肝脏疾病以及癌症等领域提供准确和有用的信息;可用于生成医学文件,如患者医疗报告、放射学报告和医疗记录等。这些文件在准确性、人性化和可读性方面得到了良好的评价,为医疗实践提供了重要的支持。
对于大模型在医疗健康领域的应用,此前中国信通院云大所副所长闵栋提出了9个应用场景,包括辅助决策、治疗方案生成和质量控制等。刘加林团队的研究已经证明了大模型在辅助决策方面发挥了作用,还有许多大模型在问诊、影像鉴别等方面取得了不错的准确度,但在其他多个应用场景中,医疗大模型的应用效果仍需进一步研究。
闵栋近日发文表示,目前我国医疗大模型产业仍在发展早期,且大多厂商对标ChatGPT同步发展,处于跟进复刻的阶段,创新性总体偏弱。当国内大模型技术积累达到一定阶段,不同应用定位的模型优势将会在产业中显现出来,呈现出差异化,这也是大模型商业落地的主要途径。
随着各厂商大模型产品的研发和应用,2024年医疗健康领域也将出现覆盖不同应用场景的医疗大模型,更多相关研究工作也将逐步展开和验证。
大模型“通病”在医疗领域要零容忍
CDSreport发现,尽管大模型在医疗健康领域应用效果的研究成果目前仍在少数,但对其存在的隐患已逐渐形成共识。上海市数据科学重点实验室主任、复旦大学附属眼耳鼻喉科医院等多家机构特聘教授肖仰华发表的论文阐述了大模型在医疗应用中的局限性。
1. 仅根据文字记载难以习得专家经验
医疗是一类典型的严肃、复杂应用场景,对大模型的准确性、精确性、安全性、可靠性、认知能力均提出更高要求。例如医生在对患者进行诊断时,不仅要考虑过往病史,还要通过场景判断患者所述是否属实,多凭借自身丰富经验解决问题。大模型难以仅从文字记载的数据中习得,与资深医疗专家水平仍有差距。
2. 无法辅助解决真实场景中的复杂决策任务
目前,以大模型为核心的人工智能技术在医学中的应用定位仍是辅助决策。ChatGPT类大模型本质上是在开放环境中实现人机对话,但是开放聊天无法辅助解决真实工作场景中的复杂决策任务。例如在疾病诊断方面,医生会根据患者的收入和医保情况制定个性化诊疗方案。要胜任此类工作,大模型需要丰富的专业知识、合理的角色定位、病情病势研判能力、复杂约束取舍能力、不完全信息下的推断能力等,大模型要从聊天能手变成医学专业助手仍需经历漫长的优化过程。
3. 幻觉问题
医疗关系到公众的生命健康,对错误需要零容忍,应用任何人工智能技术都要有系统性的解决方案才能达到医学严苛的准确性与精度要求。而生成式大模型本质上是概率模型,仍有产生错误的可能。例如,胃复安的主要成分是甲氧氯普胺,但ChatGPT回答的是天然气孔草酮。这看似严谨的回答存在基本事实错误,在应用时需要付诸极大的代价判断信息真伪,增加了应用成本。幻觉问题是大模型落地垂域应用不可避免的问题。
对于以上医疗大模型目前存在的普遍问题,肖仰华认为原因有3点:首先,大模型先天能力不足,训练语料、轮次有限都会导致学习不充分、知识有限、推理受限等问题;其次实际任务往往太复杂,大模型对复杂指令理解能力有限,进而产生幻觉;最后,由于专业领域知识相对薄弱、难获取,大模型对于某些专业知识的掌握能力有限,因此生成错误答案。
本地化部署或成2024年发展方向
如何才能解决大模型在医疗健康领域现存的问题?刘加林提出,应对数据进行审查和清洗,为大模型提供更加广泛和多样化的训练数据,涵盖不同人口群体和疾病情况,以减少偏见的影响,确保大模型的输出结果是公正和准确的。此外,为了保护患者的隐私和数据安全,需要采取严格的数据安全措施,如数据加密、访问控制和匿名化等。同时,为了提高其可信度和可接受性,需要研究算法的透明性和可解释性,包括开发解释性的模型架构、提供决策依据的解释,以及记录和审查大模型与患者之间的交互过程。
为了克服上述问题和风险,政府部门、学协会、研究机构和医疗机构等需要针对实际问题制定相关政策和监管措施,确保大模型在临床实践中的合理和安全应用。同时,还需要加强研究,提高大模型的性能和可靠性,以确保其在医疗领域的广泛应用能够带来真正的益处,并最大限度地减少风险。
为此,由中国信息通信研究院牵头,国家卫生健康委医疗服务指导管理中心以及多家医院、技术公司共同研究起草的《医疗健康行业大模型应用技术要求 第1部分:医院侧医疗服务》《医疗健康行业大模型应用技术要求 第2部分:患者侧医疗服务》《医疗健康行业大模型合成服务治理规范 第1部分:数据处理》《医疗健康行业大模型安全管理能力要求 第1部分:应用安全》四项标准于2023年9月发布。旨在对医疗健康行业大模型应用服务能力进行全方位、多角度的综合评定,通过构建全面多层的测试问题集,探查医疗健康行业大模型的知识丰富度和临床沟通能力等。
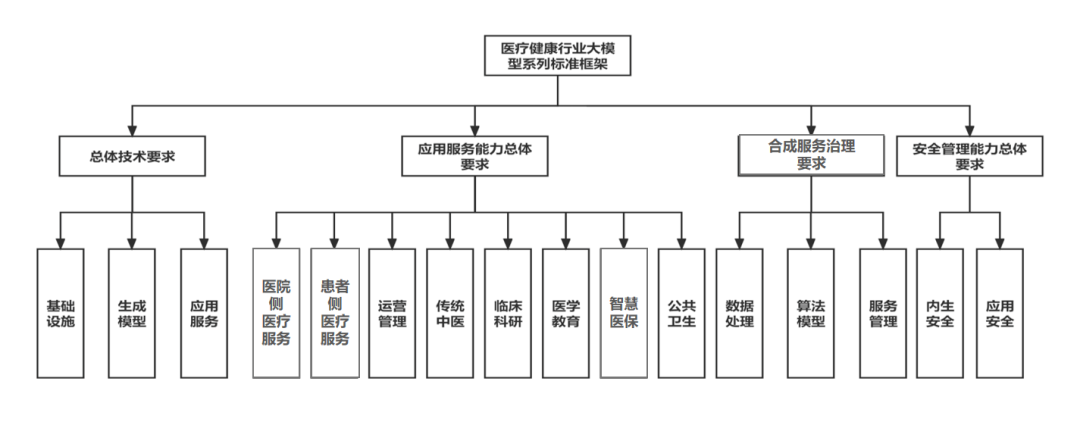
医疗健康行业大模型系列标准框架
根据中国信息通信研究院制定的“医疗健康行业大模型系列标准框架”,下一步还将陆续发布多项标准,以促进大模型在医疗健康行业的技术标准、能力建设、涵盖范围和安全要求等。
对于2024年的发展方向,中国信通院云大所数字健康部副主任冯天宜表示,一方面,大模型在医疗场景应用,还需兼顾安全性与专业性,可以通过数据清洗、标注和验证等对规范数据质量提出量化要求以控制数据质量,及时开展算法检测和修正确保模型决策透明、可解释、可追溯等手段应对内容虚假和错误的问题;另一方面,大模型的计算需要大量的算力作为支撑,但医院在算力部署等方面仍存在短板,因此轻量化、本地化部署的大模型将成为重要发展方向。
目前,已有厂商已经解决了大模型在医疗机构私有化部署的问题。例如惠每科技与英特尔联合开发了基于CPU的大模型推理技术,使惠每医疗大模型可与医院部署的CDSS无缝集成,无需重新对接或购买GPU服务器,帮助医院低成本地使用大模型。目前惠每医疗大模型已经具备鉴别诊断和病历自动生成能力,未来在CDSS提供高质量医疗数据的基础上,其可在更多诊疗环节展现能力。
参考资料:
1. 四川大学华西医院信息中心刘加林教授团队:ChatGPT在临床实践中的应用.刘加林等.华西医学时间.2023.07.04
2. 是时候,给医疗大模型来一套标准试题.闵栋. 财经大健康.2023.12.11
3. 大规模生成式语言模型在医疗领域的应用:机遇与挑战.肖仰华,徐一丹.医学信息学杂志.2023,44(9):1-11
4. AI大模型竞相入局医疗赛道,如何应对各类落地挑战?.邹臻杰.第一财经.2024.01.08
成为我们的
合作伙伴